
Distributed Database:- Distributed database system consists of a collection of sites, each of which maintains a local database system. Each site is able to process local transactions, those transactions that access data only in that single site. In addition, a site may participate in the execution of global transactions, those transactions that access data in several sites. The execution of global transactions requires communication among the sites.
We can define a distributed database as a collection of multiple logically interrelated database distributed over a computer network, and the software that manages the distributed database is called a distributed database management system (DDBMS).
In a distributed database system, the database is stored on several computers. The computers in a distributed system communicate with each other through various communication media such as a telephone line.
The main difference between centralized and distributed database systems is that in a centralized system the data resides in one single location, while is distributed, the data resides in several locations.
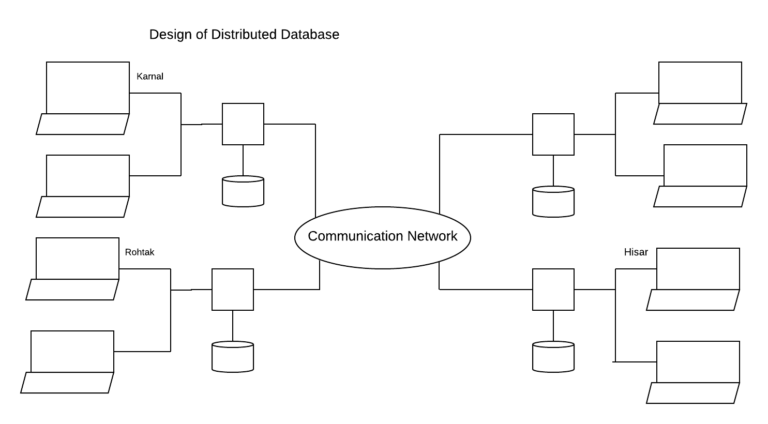
For the purpose of designing the database
The following issues must be considered.
1. How to partition the database into fragments?
i.e. data fragmentation.
2. Which fragments to replicate. i.e. Data Duplication
3. Where to locate those fragments & replies?
Data Fragmentation
A fragment is a logical unit resulting from the breaking of the database.
There are three different schemes for fragmenting a relation;
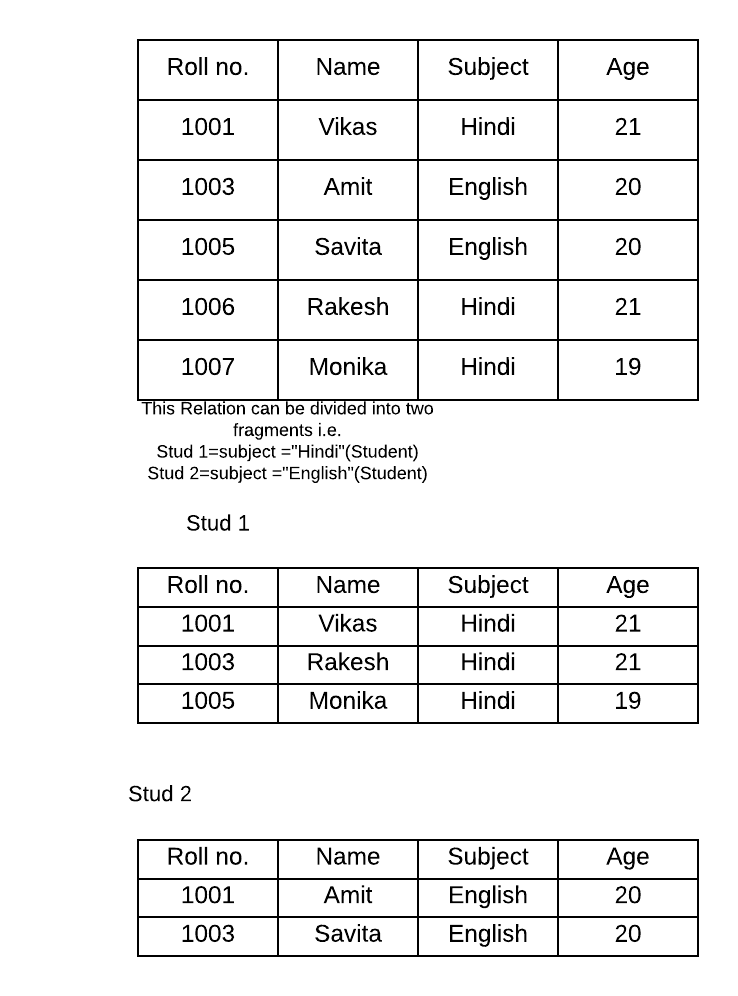
1. Horizontal Fragmentation
The relation r is partitioned into a number of subsets r1, r2….rn. Each subset consists of a number of tuples of relation r. Each tuple of relation r must belong to one of the segments.
Eg. Consider the following relation
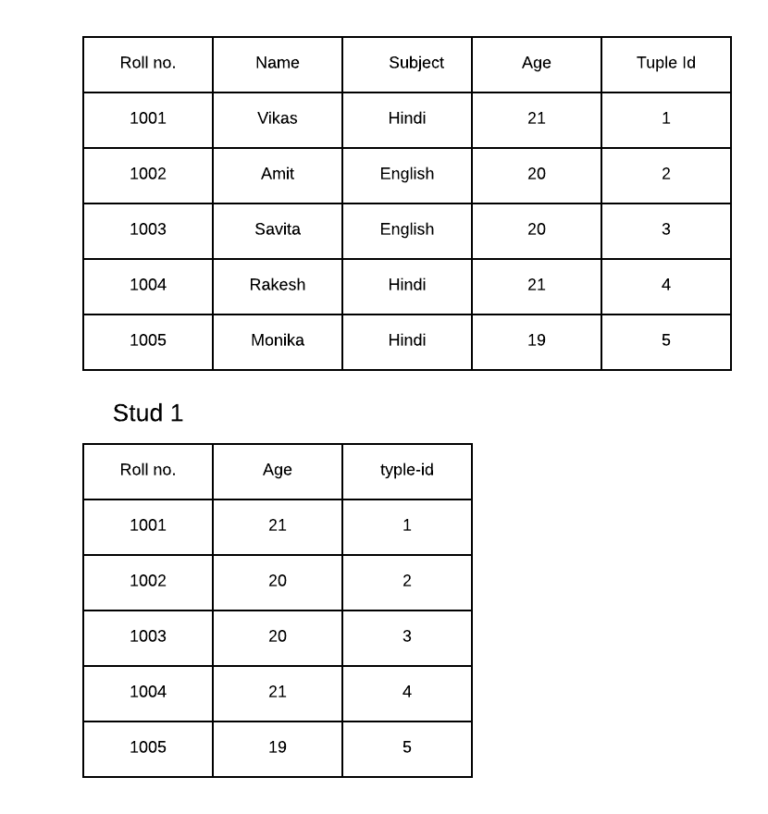
2. Vertical Fragmentation
Vertical fragmentation divides a relation vertically by columns. More generally a vertical fragmentation is accomplished by adding a special attribute called a tuple-id.
Eg.
Stud1=II(Roll No, Age, Tuple-id)
Stud2=II(Name, Subject, Tuple-id)
3. Mixed or Hybrid
Hybrid is a combination of horizontal & vertical fragmentation of a relation.
The above relation STUDENT can be divided into four different mixed fragments.
Data Replication
The system maintains several identical copies of the relation. Each copy is stored in a different location(site), resulting in data replication.
Advantage
> Availability
If one of the sites containing r fails, then the relation r may be found in another site.
> Increased Parallelism
In the case where the majority of access to relation 7 results in only the reading of the relation, several sites can process queries involving r in parallel.
Disadvantages
- Increased overhead on update
- Large storage requirement
- Chances of inconsistency
Data Allocation
Each relation or fragment of the relation must be assigned to a particular site in the distributed system. This process is called data allocation or data distribution. The choice of sites & the degree of replication depends on the performance & availability goals of the system & on the types & frequencies of transactions submitted at each site.